
Use List.PositionOf() To Find The First Row of Data In An Excel File
/Excel can be one of the worst data sources for Power BI. Its greatest strength for users is also its greatest weakness for Power BI developers getting data out of it via Power Query - it is almost unlimited in its flexibility. So end users will do things that cause your refreshes to fail. Things like inserting columns, rows, merging cells, etc. I’m going to show you how to find data in a spreadsheet when users add or remove rows above the table you need. Consider the spreadsheet data below:

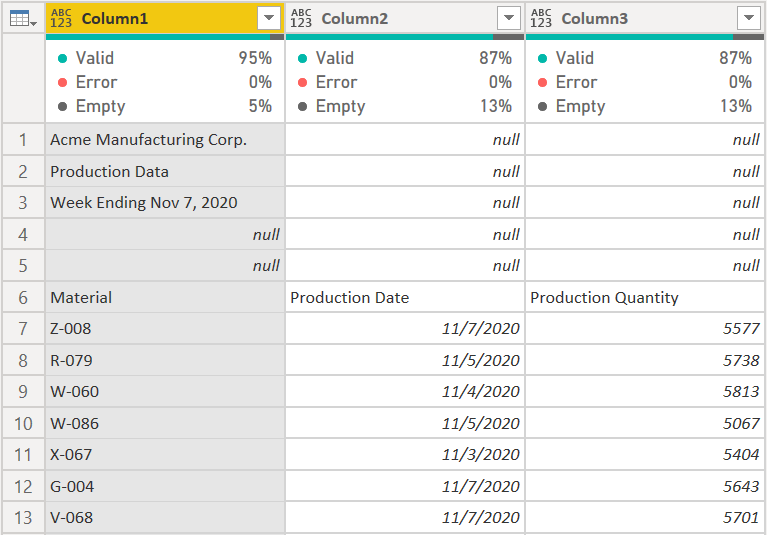
This is a simple grid of data. Ideally this would be in an Excel table, but often a Power BI developer cannot control how the data comes in, and most users still do not use Excel tables. So I call this a grid of data. And the problem with a grid of data is when it moves and you use Power Query to get the data, it will be missing information. For example, when you bring this Excel file into Power Query, it looks like this:
Fixing this is simple:
On the Home ribbon in Power Query, select Remove Rows, then Remove Top Rows, then type in the number 5.
On the Home ribbon, select “Use first row as headers”
Now it looks like this:
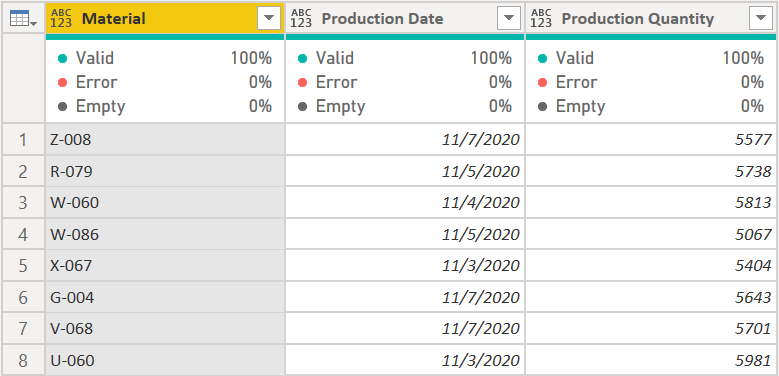
Perfect! We have good data. Next week, however, the user accumulating the production data add a few rows at the top of the file to include some notes about one of the facilities being down for maintenance one of the days.

Now the grid of data starts on row 8, not row 6 like before. When Power Query does the refresh, you get this:

Now you have a mess. the column names will load into Power BI as Column1, Column2, and Column3 if it loads at all. More likely you’ll just get a refresh error. If you had changed the data types (as you should) it would have broken right off of the bat when it tried to change the “Material” column to text. The Material column no longer exists! It is just Column1. The Production Date column is worse as if you tried to change that to a Date data type, that itself will generate errors because there is text in that column. In other words, this is a total mess. You could edit your Power Query code to skip the first 7 rows instead of the first 5, but that just becomes a cat and mouse game when the users adds or removes rows again in the future.
The better solution is to dynamically find the first row of data. Power Query has a function that will help with this. It is called List.PositionOf(). Basically what it does is it takes a list and tell you what position your search item is on in the list. Let’s walk through it with our new production data with the extra rows.
First, delete the Promoted Headers and Removed Top rows steps you created earlier so we are back to the below image. If there are any Changed Type steps, get rid of those as well. You should only have the Source and Navigation steps in the Applied Steps at the right side of the Power Query window.

We want to find the word “Material” here. Right-Click on the “Navigation Step” in the Applied Steps pane and click Insert After. It will create a Custom1 step that will simply have this in the formula bar: = Sheet1_Sheet - which is just pointing to the Navigation step. Change that to this:
= Sheet1_Sheet[Column1]
We told it to only show us [Column1] from the Sheet1_Sheet step. Sheet1_Sheet is just the name of the table. Confusingly Power Query hides this in the Navigation step. Here we can clearly see it. Note: If you are using this technique at any time after the Navigation step, the table name is just the name of the Applied Step. For example, if you had selected the first three columns and then selected Remove Other Columns from the ribbon, your step would be “Remove Other Columns” and the table name is #”Remove Other Columns” - the # and quotes are necessary if any table name has spaces in it.
Most Applied Steps in Power Query are just tables. But this one is not. You’ll notice after adding [Column1] after it, the name of the first column, it is now a list.

Now we are getting somewhere. Time to use List.PositionOf. Edit the formula above to this, and you’ll get the following screen.
= List.PositionOf(Sheet1_Sheet[Column1], "Material")

It found the word “Material” on row 7. Wait a minute… on the image above with the list, it shows Material on row 8. Power Query indexes at 0, so the first row isn’t 1, but 0. So Material is in position 7 in the list. This actually helps us with the next step.
Right-click on the Custom1 step and rename it something useful, like PositionOfMaterial. I recommend you use no spaces for this step. It makes referencing it later easier.
Right-click on PositionOfMaterial again and Insert Step After. Now, we need to get our original table and skip the first 7 rows, right? When you use the Remove Top Rows feature, Power Query creates a step using the Table.Skip function. We are going to do that manually. In the formula bar, you probably see =PositionOfMaterial and it still show the value. Get rid of that and type this:
= Table.Skip(Sheet1_Sheet, PositionOfMaterial)
Remember, our original table was Sheet1_Sheet. Table.Skip has this syntax: Table.Skip(TableName, RowsToSkip). TableName is Sheet1_Sheet in this case, and instead of hardcoding the RowsToSkip, we are using a variable, our PositionOfMaterial step. Now our data looks like this:

Now you can promote the first row as headers, change your data types, and continue on. Next week when our production supervisor turns in the report, it won’t matter if Material on on row 1 or 100, List.PositionOf() will find it for us and dynamically set the top of the table. Even if all of the header is deleted, List.PositionOf() will return 0 for the position of Material, and Table.Skip will effectively do nothing, skipping 0 rows. So it will still work for us.
This method will work with any kind of data, but Excel is the most common use for it. Most other data sources, like databases, SharePoint Lists, true Excel tables, and even CSV files, don’t have data moving up and down on you.